The Most Cited, Least Understood Concept in Qualitative Research
Ask any qualitative researcher when to stop collecting data and you will hear the same answer: "When you reach saturation." Press them on what that means operationally and things get vague fast.
Data saturation -- the point at which new data yields no new themes or insights -- is simultaneously the most cited justification for sample size in qualitative research and one of the least rigorously defined concepts in the methodology toolkit. It functions more as a rhetorical device than an analytical criterion.
This matters practically because teams making product decisions based on qualitative research need to know: did you talk to enough people? And "we reached saturation" is often a post-hoc rationalization rather than a prospective decision rule.
The Origin Story
Saturation entered qualitative methodology through Glaser and Strauss's 1967 work on grounded theory. Their concept of "theoretical saturation" was specific: you stop sampling when new data no longer contributes to the development of your emerging theory. The unit of analysis was theoretical categories, not raw themes.
But as the concept migrated from grounded theory into general qualitative practice, it lost its theoretical anchoring. "Saturation" became shorthand for "I stopped hearing new things" -- which is a much weaker claim that depends entirely on what you are listening for.
This conceptual drift has real consequences for research operations. If saturation is your stopping rule but you cannot define it precisely, every sample size decision becomes arbitrary dressed up as methodological.
Why Saturation Is Harder Than It Looks
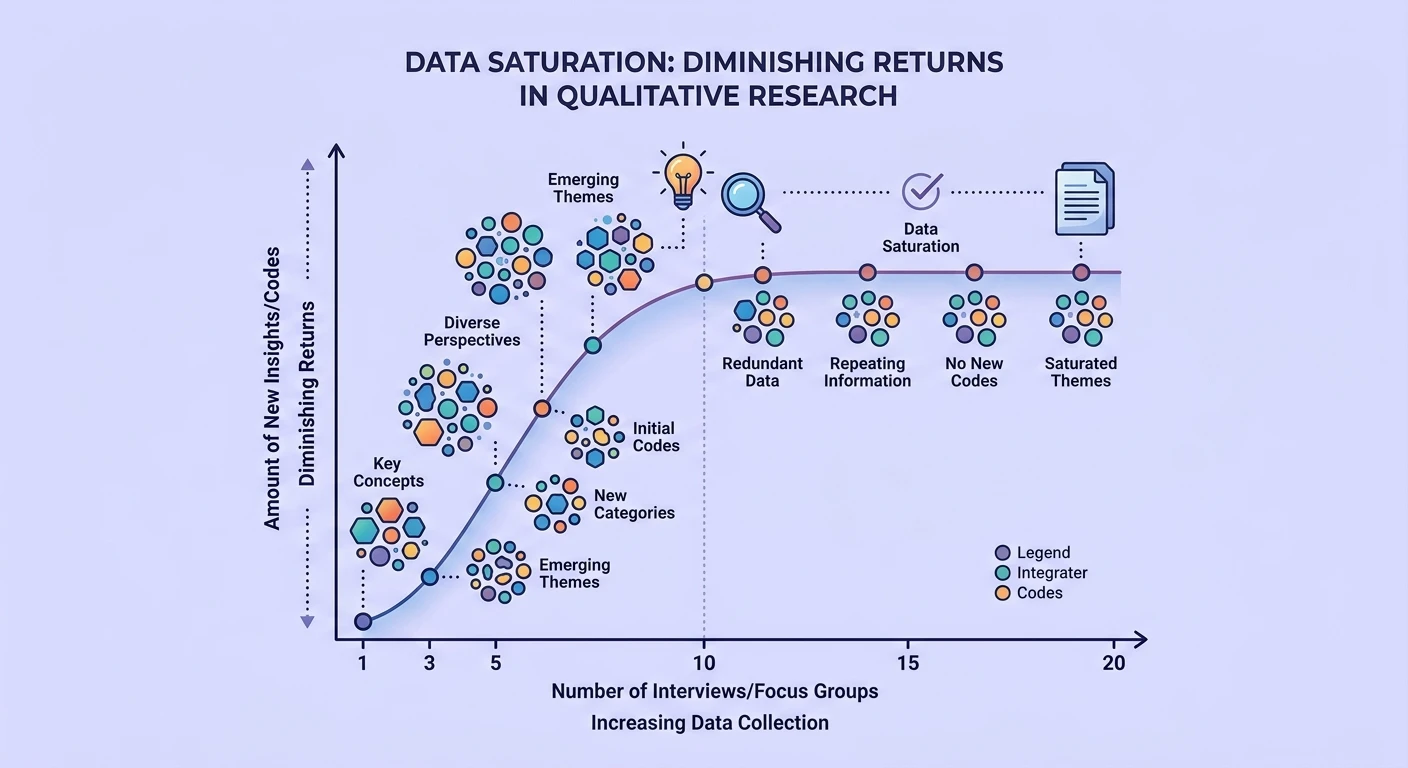
The granularity problem. Saturation depends on the level of abstraction. At a high level ("users find onboarding confusing"), you might reach saturation after 5 interviews. At a fine-grained level ("users with technical backgrounds find step 3 confusing because the terminology assumes marketing knowledge"), you might need 25. The stopping point is determined by how closely you look, not by some objective property of the data.
The analyst dependence problem. Different researchers coding the same transcripts identify different themes. If saturation means "no new themes," it is analyst-specific. One researcher reaches saturation at interview 8; another finds new codes at interview 15 from the same dataset. This is not a bug in the method -- it reflects the interpretive nature of qualitative analysis -- but it undermines saturation as an objective stopping criterion.
The question scope problem. Broad research questions generate more themes and require more data. Narrow questions saturate faster. But researchers often begin with broad questions that narrow during analysis, meaning the saturation threshold shifts during the study itself.
The homogeneity assumption. Saturation assumes your sample is drawn from a relatively homogeneous population. If your users span radically different contexts -- enterprise vs. startup, technical vs. non-technical, North America vs. Southeast Asia -- you may never reach saturation because each new segment introduces new themes. The concept works best for research participant archetypes that share meaningful common ground.
What the Empirical Evidence Says
Recent methodological research has attempted to quantify saturation empirically. Guest, Bunce, and Johnson's influential 2006 study found that 92% of codes were identified within the first 12 interviews in their dataset. But this was a single study on a relatively homogeneous population with a specific analytical approach. Generalizability is limited.
More recent work suggests that for common UX research questions with reasonably homogeneous populations, 6-12 interviews capture the majority of themes. But "majority" is doing heavy lifting here. The question is whether the themes you miss in interviews 13-20 are the ones that matter most for your product decision.
Often they are. The silence problem in user interviews -- what participants do not say -- means that the most important insights sometimes come from outlier participants who break the pattern rather than confirm it.
Better Alternatives to the Saturation Heuristic
Information power. Malterud et al.'s concept of information power offers a more nuanced framework. Sample size depends on: study aim (broad vs. narrow), sample specificity (homogeneous vs. diverse), theory (established vs. exploratory), dialogue quality (strong vs. weak), and analysis strategy (case vs. cross-case). More information power per participant means fewer participants needed.
Pragmatic saturation indicators. Rather than claiming absolute saturation, report concrete indicators: "After interview 10, the last 3 interviews generated no new level-1 codes and only 2 new level-2 codes, suggesting diminishing returns for this research question." This is transparent and falsifiable.
Decision adequacy. Ask: do we have enough evidence to make the decision this research is supposed to inform? This reframes the question from methodological purity to practical utility. Sometimes 5 interviews provide sufficient evidence for a design decision. Sometimes 30 are not enough for a strategic pivot.
Continuous discovery models. Rather than treating saturation as a stopping point, continuous discovery approaches treat research as an ongoing stream where insights accumulate over time. There is no single stopping point because the research never fully stops.
How AI Changes Saturation Analysis
AI-powered analysis tools are making saturation assessment more rigorous by enabling real-time code frequency monitoring. When you can see your codebook development curve live -- watching new codes emerge and plateau across interviews -- the saturation judgment becomes data-informed rather than purely intuitive.
This connects to broader shifts in how AI is reshaping qualitative analysis. When coding is faster, you can analyze as you go rather than waiting until all interviews are complete. This enables adaptive sampling: if new themes are still emerging after interview 8, you recruit more participants. If the code development curve has flattened, you can stop with confidence.
The combination of AI-assisted coding and structured output engineering makes it possible to generate saturation metrics automatically -- tracking code emergence rates, theme stability, and coverage completeness across the data corpus.
Practical Recommendations
- Never claim saturation without evidence. Report your code development curve, not just the final count.
- Specify your saturation criteria prospectively. Before data collection, define what level of thematic stability you require and at what granularity.
- Acknowledge the limits. "We identified X themes across Y interviews. Additional sampling may reveal further variation, particularly among [specific segments not well-represented]."
- Use saturation as one input, not the only input. Budget, timeline, access, and decision urgency all legitimately influence sample size.
- Consider information power instead. A well-designed study with high-quality participants and focused questions needs fewer participants than a broad exploratory study with loose inclusion criteria.
The Honest Answer
The honest answer to "how many interviews do I need?" is: it depends, and anyone who gives you a single number is oversimplifying. Saturation is a useful concept when treated as a heuristic rather than a bright-line rule. The goal is not to prove you talked to enough people. The goal is to generate sufficient evidence to make a defensible decision -- and to be transparent about the limits of that evidence.
Researchers who embrace this ambiguity produce better work than those who hide behind the false certainty of "we reached saturation at N=12."
*Need to make defensible sample size decisions for your next qualitative study? Book a session to see how Qualz helps teams monitor saturation in real time with AI-powered code tracking.*